Esempi e applicazioni
In questa lezione esploreremo alcuni esempi di algoritmi variazionali e come applicarli:
- Come scrivere un algoritmo variazionale personalizzato
- Come applicare un algoritmo variazionale per trovare gli autovalori minimi
- Come utilizzare gli algoritmi variazionali per risolvere casi d'uso applicativi
Nota che il framework dei pattern Qiskit può essere applicato a tutti i problemi che introduciamo qui. Tuttavia, per evitare ripetizioni, richiameremo esplicitamente i passi del framework solo in un caso di esempio eseguito su hardware reale.
Definizioni del problema
Immagina di voler usare un algoritmo variazionale per trovare l'autovalore del seguente osservabile:
Questo osservabile ha i seguenti autovalori:
E i seguenti autostati:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
VQE personalizzato
Esploreremo prima come costruire un'istanza VQE manualmente per trovare il minimo autovalore di . Questo incorporerà una serie di tecniche che abbiamo trattato nel corso.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
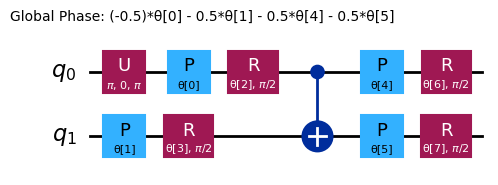
Inizieremo il debug su simulatori locali.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Impostiamo ora un insieme iniziale di parametri:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Possiamo minimizzare questa funzione di costo per calcolare i parametri ottimali
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Poiché questo problema giocattolo utilizza solo due qubit, possiamo verificare il risultato usando il solutore di algebra lineare di NumPy.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Come puoi vedere, il risultato è estremamente vicino a quello ideale.
Esperimenti per migliorare velocità e precisione
Aggiungere uno stato di riferimento
Nell'esempio precedente non abbiamo usato alcun operatore di riferimento . Proviamo ora a capire come si può ottenere lo stato ideale . Considera il seguente circuito.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Possiamo verificare rapidamente che questo circuito ci restituisce lo stato desiderato.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Ora che abbiamo visto come si presenta un circuito che prepara lo stato soluzione, sembra ragionevole usare un gate di Hadamard come circuit di riferimento, in modo che l'ansatz completo diventi:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
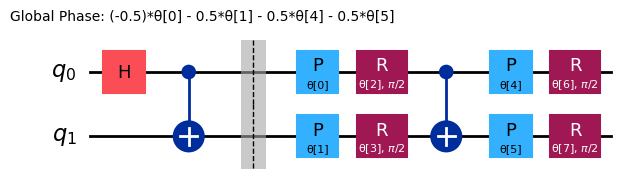
Per questo nuovo circuito, la soluzione ideale potrebbe essere raggiunta con tutti i parametri impostati a , il che conferma che la scelta del circuit di riferimento è ragionevole.
Confrontiamo ora il numero di valutazioni della funzione di costo, le iterazioni dell'ottimizzatore e il tempo impiegato rispetto al tentativo precedente.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Usando i parametri ottimali per calcolare il minimo autovalore:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
A seconda del sistema specifico, questo potrebbe o meno tradursi in un miglioramento della velocità o della precisione in questo esempio su scala molto ridotta. Il punto importante è che partire da stati di riferimento fisicamente motivati diventa sempre più importante per migliorare velocità e precisione al crescere dei problemi.
Cambiare il punto iniziale
Ora che abbiamo visto l'effetto dell'aggiunta dello stato di riferimento, vedremo cosa succede quando si scelgono punti iniziali diversi. In particolare useremo e .
Ricorda che, come discusso quando è stato introdotto lo stato di riferimento, la soluzione ideale si troverebbe con tutti i parametri a , quindi il primo punto iniziale dovrebbe richiedere meno valutazioni.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Aggiustando il punto iniziale a :
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Sperimentando con diversi punti iniziali, potresti riuscire ad ottenere una convergenza più rapida e con meno valutazioni della funzione.
Sperimentare con ottimizzatori diversi
Possiamo modificare l'ottimizzatore usando l'argomento method di minimize di SciPy, con ulteriori opzioni disponibili qui. In origine abbiamo usato un minimizzatore vincolato (COBYLA). In questo esempio esploreremo l'uso di un minimizzatore non vincolato (BFGS) al suo posto.
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
Esempio VQD
Qui implementiamo esplicitamente il framework Qiskit patterns.
Passo 1: Mappa gli input classici su un problema quantistico
Invece di cercare solo il valore minimo degli autovalori dei nostri osservabili, ne cercheremo tutti e (dove ).
Ricorda che le funzioni di costo di VQD sono:
Questo è particolarmente importante perché un vettore (in questo caso ) deve essere passato come argomento quando definiamo l'oggetto VQD.
Inoltre, nell'implementazione di VQD in Qiskit, invece di considerare gli osservabili effettivi descritti nel notebook precedente, le fedeltà vengono calcolate direttamente tramite l'algoritmo ComputeUncompute, che sfrutta una primitiva Sampler per campionare la probabilità di ottenere per il circuito
. Questo funziona proprio perché tale probabilità è
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
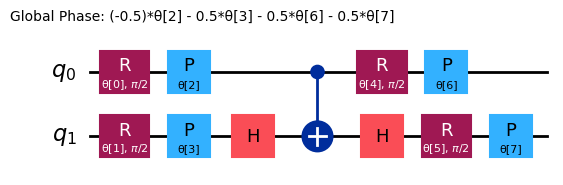
Iniziamo esaminando il seguente osservabile:
Questo osservabile ha i seguenti autovalori:
E autostati:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
Utilizzeremo la seguente funzione per calcolare la penalità di sovrapposizione. Tieni presente che questa fa ancora parte della mappatura del problema sui circuiti quantistici. Tuttavia, come discusso nella lezione precedente, questa funzione calcola la sovrapposizione tra un circuito variazionale corrente e il circuito ottimizzato proveniente da uno stato precedente a energia/costo inferiore. Il nuovo circuito generato deve anche essere transpilato per funzionare su hardware reale. Abbiamo già visto questa funzione in precedenza, usata su un simulatore. Qui dobbiamo già considerare la transpilazione e la relativa ottimizzazione per quando utilizziamo un backend reale, da cui le righe relative a if realbackend == 1. Questo mescola un po' il passo 2, ma chiameremo esplicitamente il passo 2 più avanti.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Aggiungiamo ora la funzione di costo di VQD. Nota che rispetto alla lezione precedente abbiamo due argomenti aggiuntivi (realbackend e backend) per gestire la transpilazione quando utilizziamo backend reali.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Ancora una volta, utilizzeremo i simulatori per il debug e poi passeremo all'hardware reale.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Qui introduciamo il numero di stati che vogliamo calcolare, le penalità e un insieme di parametri iniziali x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Testeremo ora l'algoritmo usando i simulatori:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Questi risultati sono abbastanza vicini a quelli attesi, a parte l'errore di approssimazione e la fase globale. Potremmo aggiustare la tolleranza sull'ottimizzatore classico e/o le penalità per la sovrapposizione degli statevector per ottenere valori più precisi.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Cambiare i beta
Come menzionato nella lezione precedente, i valori di devono essere maggiori della differenza tra gli autovalori. Vediamo cosa succede quando non soddisfano questa condizione con
con autovalori
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Questa volta l'ottimizzatore restituisce lo stesso stato come soluzione proposta per tutti gli autostati: il che è chiaramente sbagliato. Ciò accade perché i beta erano troppo piccoli per penalizzare l'autostato minimo nelle successive funzioni di costo. Pertanto, non è stato escluso dallo spazio di ricerca effettivo nelle iterazioni successive dell'algoritmo, ed è sempre stato scelto come la migliore soluzione possibile.
Ti consigliamo di sperimentare con i valori di , assicurandoti che siano maggiori della differenza tra gli autovalori.
Passo 2: Ottimizza il problema per l'esecuzione quantistica
Per eseguire questo su hardware reale, dobbiamo ottimizzare i circuiti quantistici per il computer quantistico scelto. Per i nostri scopi, utilizzeremo semplicemente il backend meno occupato.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Transpileremo il nostro circuito utilizzando un preset pass manager con livello di ottimizzazione 3.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Passo 3: Esegui usando le primitive Qiskit
Avendo cura di reimpostare i nostri beta a valori sufficientemente elevati, possiamo ora eseguire il calcolo su hardware quantistico reale.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Passo 4: Post-elaborazione, restituisci il risultato in formato classico
Il nostro output è strutturalmente simile a quanto discusso nelle lezioni e negli esempi precedenti. Tuttavia c'è qualcosa di problematico nei risultati sopra, da cui possiamo trarre un messaggio di avvertimento nel contesto degli stati eccitati. Per limitare il tempo di calcolo usato in questo esempio didattico, abbiamo impostato un numero massimo di iterazioni per l'ottimizzatore classico che era potenzialmente troppo basso: 200 iterazioni. Un calcolo precedente, effettuato su un simulatore, non è riuscito a convergere in 200 iterazioni. Il nostro ha invece convergito... ma con quale tolleranza? Non abbiamo specificato una tolleranza affinché COBYLA si consideri "converso". Uno sguardo al valore della funzione e il confronto con le esecuzioni precedenti ci dice che COBYLA non era affatto vicino alla convergenza con la precisione richiesta.
C'è un altro problema: l'energia del primo stato eccitato sembra essere inferiore all'energia dello stato fondamentale! Prova a spiegare come potrebbe accadere. Suggerimento: è correlato al punto di convergenza appena affrontato. Questo comportamento è spiegato in dettaglio più avanti, dopo che VQD è applicato alla molecola H2.
Chimica quantistica: risolutore dello stato fondamentale e degli stati eccitati
Il nostro obiettivo è minimizzare il valore atteso dell'osservabile che rappresenta l'energia (Hamiltoniana ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
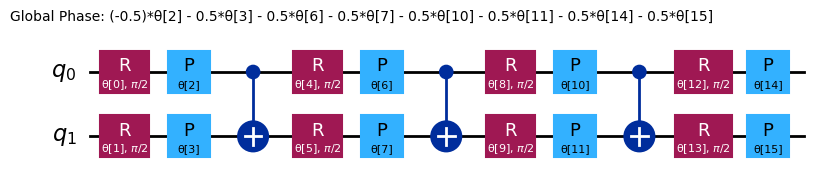
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Impostiamo ora un insieme iniziale di parametri:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Possiamo minimizzare questa funzione di costo per calcolare i parametri ottimali, e possiamo verificare il codice prima usando un simulatore locale.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
Il valore minimo della funzione di costo (-1.857...) è l'energia dello stato fondamentale della molecola H2, espressa in hartree.
Stati eccitati
Possiamo anche sfruttare VQD per risolvere stati totali (lo stato fondamentale e il primo stato eccitato).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Aggiungeremo il calcolo della sovrapposizione:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Hardware reale e un ultimo avvertimento
Per eseguire questo su hardware reale, dobbiamo ottimizzare i circuiti quantistici per il computer quantistico scelto. Ai nostri scopi, useremo semplicemente il backend meno occupato.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Utilizzeremo un pass manager preimpostato per la trasposizione e ottimizzeremo al massimo il circuito usando il livello di ottimizzazione 3.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Poiché VQD è altamente iterativo, eseguiremo tutti i passaggi all'interno di una sessione Runtime, in modo che i nostri job vengano accodati solo all'inizio e non tra ogni aggiornamento dei parametri. Nulla cambia nella sintassi della funzione di costo o dell'estimator.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
L'energia dello stato fondamentale ottenuta (-1.83 hartree) non è troppo distante dal valore corretto (-1.85 hartree). Tuttavia, l'energia dello stato eccitato è abbastanza lontana dal valore atteso. Questo è simile al comportamento erroneo che abbiamo visto prima in questa lezione. L'energia riportata per lo stato eccitato è quasi uguale a quella dello stato fondamentale. Nel caso precedente, abbiamo persino visto un'energia dello stato eccitato inferiore all'energia dello stato fondamentale riportata.
Non è possibile che un calcolo variazionale produca un'energia inferiore alla vera energia dello stato fondamentale. Nel caso precedente, l'energia dello stato fondamentale ottenuta non era molto vicina a quella vera. Poiché in quel caso non abbiamo ottenuto la vera energia dello stato fondamentale, non vi è contraddizione. Nel caso attuale, l'energia dello stato fondamentale era abbastanza vicina al valore corretto, eppure l'energia dello stato eccitato sembra stranamente vicina a quello stesso valore.
Per capire meglio come sia successo, ricorda che il modo in cui troviamo uno stato eccitato è richiedendo che lo stato variazionale sia ortogonale allo stato fondamentale (usando i circuiti di sovrapposizione e i termini di penalità). Se non riusciamo a ottenere un'energia dello stato fondamentale accurata (o ci scostiamo di qualche percentuale), allora non otteniamo nemmeno un vettore dello stato fondamentale accurato! Quindi, quando richiediamo che lo stato eccitato sia ortogonale al primo stato trovato, non stavamo imponendo l'ortogonalità con il vero stato fondamentale, bensì con un'approssimazione di esso (a volte un'approssimazione scadente). Di conseguenza, lo stato eccitato non è stato costretto a essere ortogonale al vero stato fondamentale, e le stime di energia per gli stati eccitati erano in realtà piuttosto vicine all'energia dello stato fondamentale.
Questo sarà sempre un problema in VQD. Ma in linea di principio può essere corretto aumentando il numero massimo di iterazioni per l'ottimizzatore classico, imponendo una tolleranza inferiore per l'ottimizzatore classico, e possibilmente provando anche un ansatz diverso se si manca abitualmente il vero stato fondamentale. Come abbiamo visto, potrebbe anche essere necessario modificare le penalità di sovrapposizione (betas). Ma questo è davvero un problema separato. Nessuna penalità di sovrapposizione ti terrà lontano dal vero stato fondamentale, se non hai trovato una buona stima del vero stato fondamentale per il circuito di sovrapposizione.
Ottimizzazione: Max-Cut
Il problema del taglio massimo (Max-Cut) è un problema di ottimizzazione combinatoria che consiste nel dividere i vertici di un grafo in due insiemi disgiunti in modo da massimizzare il numero di archi tra i due insiemi. Più formalmente, dato un grafo non orientato , dove è l'insieme dei vertici ed è l'insieme degli archi, il problema Max-Cut chiede di partizionare i vertici in due sottoinsiemi disgiunti, e , in modo che il numero di archi con un estremo in e l'altro in sia massimizzato.
Possiamo applicare Max-Cut per risolvere vari problemi, come il clustering, la progettazione di reti e le transizioni di fase. Inizieremo creando un grafo del problema:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Questo problema può essere espresso come un problema di ottimizzazione binaria. Per ogni nodo , dove è il numero di nodi del grafo (in questo caso ), considereremo la variabile binaria . Questa variabile avrà valore se il nodo appartiene a uno dei gruppi che chiameremo , e se appartiene all'altro gruppo, che chiameremo . Indicheremo anche con (elemento della matrice di adiacenza ) il peso dell'arco che va dal nodo al nodo . Poiché il grafo è non orientato, . Possiamo quindi formulare il problema come la massimizzazione della seguente funzione di costo:
Per risolvere questo problema con un computer quantistico, esprimeremo la funzione di costo come valore atteso di un osservabile. Tuttavia, gli osservabili che Qiskit gestisce nativamente consistono in operatori di Pauli, che hanno autovalori e invece di e . Per questo motivo effettueremo il seguente cambio di variabile:
Dove . Possiamo usare la matrice di adiacenza per accedere comodamente ai pesi di tutti gli archi. Questo verrà usato per ottenere la nostra funzione di costo:
Questo implica che:
Quindi la nuova funzione di costo che vogliamo massimizzare è:
Inoltre, la tendenza naturale di un computer quantistico è trovare minimi (solitamente l'energia più bassa) anziché massimi, quindi invece di massimizzare andremo a minimizzare:
Ora che abbiamo una funzione di costo da minimizzare le cui variabili possono assumere i valori e , possiamo fare la seguente analogia con il Pauli :
In altre parole, la variabile sarà equivalente a un gate che agisce sul qubit . Inoltre:
Quindi l'osservabile che considereremo è:
al quale dovremo aggiungere il termine indipendente in seguito:
L'operatore è una combinazione lineare di termini con operatori Z sui nodi collegati da un arco (ricorda che il 0° qubit è più a destra): . Una volta costruito l'operatore, l'ansatz per l'algoritmo QAOA può essere facilmente costruito usando il circuito QAOAAnsatz dalla libreria di circuiti Qiskit.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Impostiamo ora un insieme iniziale di parametri casuali:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Qualsiasi ottimizzatore classico può essere usato per minimizzare la funzione di costo. Su un sistema quantistico reale, un ottimizzatore progettato per paesaggi di funzioni di costo non regolari di solito ottiene risultati migliori. Qui usiamo la routine COBYLA di SciPy tramite la funzione minimize.
Poiché eseguiamo iterativamente molte chiamate a Runtime, utilizziamo una sessione per eseguire tutte le chiamate all'interno di un unico blocco. Inoltre, per QAOA, la soluzione è codificata nella distribuzione di output del circuito ansatz vincolato con i parametri ottimali dalla minimizzazione. Pertanto, avremo bisogno di una primitiva Sampler e la istanzieremo con la stessa sessione. Eseguiamo poi la nostra routine di minimizzazione:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
Il vettore soluzione degli angoli dei parametri (x), inserito nel circuito ansatz, produce la partizione del grafo che stavamo cercando.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Riepilogo
Con questa lezione hai imparato:
- Come scrivere un algoritmo variazionale personalizzato
- Come applicare un algoritmo variazionale per trovare gli autovalori minimi
- Come utilizzare gli algoritmi variazionali per risolvere casi d'uso applicativi