Codifica dei dati
Introduzione e notazione
Per utilizzare un algoritmo quantistico, i dati classici devono essere in qualche modo introdotti in un circuito quantistico. Questo processo è solitamente denominato codifica dei dati, ma viene anche chiamato caricamento dei dati. Ricorda dalle lezioni precedenti il concetto di feature mapping, ovvero una mappatura delle caratteristiche dei dati da uno spazio a un altro. Il semplice trasferimento di dati classici su un computer quantistico è una sorta di mappatura, e potrebbe essere definita un feature mapping. In pratica, i feature mapping integrati in Qiskit (come z_feature_map e zz_feature_map) includono tipicamente layer di rotazione e layer di entanglement che estendono lo stato a molte dimensioni nello spazio di Hilbert. Questo processo di codifica è una parte critica degli algoritmi di machine learning quantistico e influisce direttamente sulle loro capacità computazionali.
Alcune delle tecniche di codifica descritte di seguito possono essere simulate in modo efficiente in modo classico; questo è particolarmente evidente nei metodi di codifica che producono stati prodotto (cioè, che non creano entanglement tra i qubit). Ricorda inoltre che l'utilità quantistica è più probabile laddove la complessità di tipo quantistico del dataset corrisponda bene al metodo di codifica. Quindi è molto probabile che tu finisca per scrivere i tuoi circuiti di codifica personalizzati. Qui mostriamo un'ampia varietà di possibili strategie di codifica semplicemente per permetterti di confrontarle e metterle in contrasto, e per vedere cosa è possibile fare. Alcune affermazioni molto generali possono essere fatte sull'utilità delle tecniche di codifica. Ad esempio, efficient_su2 (vedi di seguito) con uno schema di entanglement completo ha molte più probabilità di catturare caratteristiche quantistiche dei dati rispetto ai metodi che producono stati prodotto (come z_feature_map). Ma questo non significa che efficient_su2 sia sufficiente, o sufficientemente adatto al tuo dataset, per produrre un'accelerazione quantistica. Ciò richiede un'attenta considerazione della struttura dei dati da modellare o classificare. Esiste anche un compromesso con la profondità del circuito, poiché molti feature map che effettuano un entanglement completo dei qubit in un circuito producono circuiti molto profondi, troppo profondi per ottenere risultati utilizzabili sui computer quantistici odierni.
Notazione
Un dataset è un insieme di vettori di dati: , dove ogni vettore è di dimensione , ovvero . Questo potrebbe essere esteso a caratteristiche dei dati complesse. In questa lezione, utilizzeremo occasionalmente queste notazioni per l'insieme completo e i suoi elementi specifici come . Tuttavia, ci riferiremo principalmente al caricamento di un singolo vettore dal nostro dataset alla volta, e spesso faremo riferimento semplicemente a un singolo vettore di caratteristiche come .
Inoltre, è comune usare il simbolo per riferirsi al feature mapping del vettore di dati . Nell'informatica quantistica in particolare, è comune riferirsi alle mappature usando una notazione che enfatizza la natura unitaria di queste operazioni. Si potrebbe correttamente usare lo stesso simbolo per entrambe; entrambe sono feature mapping. Nel corso di questo corso, tendenzialmente utilizzeremo:
- quando discutiamo di feature mapping nel machine learning in generale, e
- quando discutiamo di implementazioni circuitali dei feature mapping.
Normalizzazione e perdita di informazione
Nel machine learning classico, le caratteristiche dei dati di addestramento vengono spesso "normalizzate" o ridimensionate, il che migliora spesso le prestazioni del modello. Un metodo comune per farlo è la normalizzazione min-max o la standardizzazione. Nella normalizzazione min-max, le colonne delle caratteristiche della matrice di dati (ad esempio, la caratteristica ) vengono normalizzate:
dove min e max si riferiscono al minimo e al massimo della caratteristica sui vettori di dati nel dataset . Tutti i valori delle caratteristiche ricadono quindi nell'intervallo unitario: per tutti , .
La normalizzazione è anche un concetto fondamentale nella meccanica quantistica e nell'informatica quantistica, ma è leggermente diversa dalla normalizzazione min-max. La normalizzazione nella meccanica quantistica richiede che la lunghezza (nel contesto dell'informatica quantistica, la 2-norma) di un vettore di stato sia uguale all'unità: , garantendo che le probabilità di misura sommino a 1. Lo stato viene normalizzato dividendo per la 2-norma; cioè, ridimensionando
Nell'informatica quantistica e nella meccanica quantistica, questa non è una normalizzazione imposta dalle persone sui dati, ma una proprietà fondamentale degli stati quantistici. A seconda dello schema di codifica scelto, questo vincolo può influire sul modo in cui i dati vengono ridimensionati. Ad esempio, nella codifica in ampiezza (vedi di seguito), il vettore di dati viene normalizzato come richiesto dalla meccanica quantistica, e questo influisce sulla scala dei dati codificati. Nella codifica di fase, si raccomanda di ridimensionare i valori delle caratteristiche come in modo che non vi sia perdita di informazione dovuta all'effetto modulo- della codifica nell'angolo di fase di un qubit[1,2].
Metodi di codifica
Nelle prossime sezioni, faremo riferimento a un piccolo dataset classico di esempio composto da vettori di dati, ciascuno con caratteristiche:
Nella notazione introdotta sopra, potremmo dire che la caratteristica del vettore di dati nel nostro insieme è ad esempio.
Codifica in base
La codifica in base codifica una stringa di bit classici in uno stato della base computazionale di un sistema a qubit. Prendiamo ad esempio Questo può essere rappresentato come una stringa di bit come , e da un sistema a qubit come lo stato quantistico . Più in generale, per una stringa di bit: , il corrispondente stato a qubit è con per . Nota che questo riguarda una singola caratteristica.
La codifica in base nell'informatica quantistica rappresenta ogni bit classico come un qubit separato, mappando la rappresentazione binaria dei dati direttamente sugli stati quantistici nella base computazionale. Quando è necessario codificare più caratteristiche, ciascuna viene prima convertita nella sua forma binaria e poi assegnata a un gruppo distinto di qubit — un gruppo per caratteristica — dove ogni qubit riflette un bit nella rappresentazione binaria di quella caratteristica.
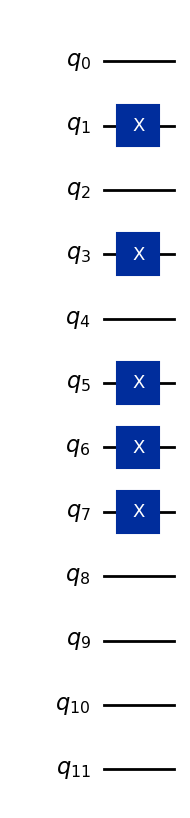
Come esempio, codifichiamo il vettore (5, 7, 0).
Supponiamo che tutte le caratteristiche siano memorizzate in quattro bit (più del necessario, ma sufficienti per rappresentare qualsiasi intero a una cifra in base 10):
5 → binario 0101
7 → binario 0111
0 → binario 0000
Queste stringhe di bit sono assegnate a tre gruppi di quattro qubit, quindi lo stato complessivo a 12 qubit nella base è:
Qui, i primi quattro qubit rappresentano la prima caratteristica, i successivi quattro la seconda caratteristica, e gli ultimi quattro la terza caratteristica. Il codice seguente converte il vettore di dati (5,7,0) in uno stato quantistico, ed è generalizzato per fare lo stesso con altre caratteristiche a singola cifra.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Verifica la tua comprensione
Leggi la domanda seguente, rifletti sulla tua risposta, poi clicca il triangolo per rivelare la soluzione.
Scrivi del codice per codificare il primo vettore del nostro dataset di esempio :
utilizzando la codifica in base.
Risposta:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Codifica in ampiezza
La codifica in ampiezza codifica i dati nelle ampiezze di uno stato quantistico. Rappresenta un vettore di dati classico -dimensionale normalizzato, , come le ampiezze di uno stato quantistico a qubit, :
dove è la stessa dimensione dei vettori di dati di prima, è l'-esimo elemento di e è l'-esimo stato della base computazionale. Qui, è una costante di normalizzazione da determinare a partire dai dati da codificare. Questa è la condizione di normalizzazione imposta dalla meccanica quantistica:
In generale, questa è una condizione diversa dalla normalizzazione min/max utilizzata per ciascuna caratteristica su tutti i vettori di dati. Il modo in cui questo viene gestito dipenderà dal tuo problema specifico. Ma la condizione di normalizzazione della meccanica quantistica qui sopra non può essere aggirata.
Nella codifica in ampiezza, ogni caratteristica in un vettore di dati è memorizzata come l'ampiezza di un diverso stato quantistico. Poiché un sistema di qubit fornisce ampiezze, la codifica in ampiezza di caratteristiche richiede qubit.
Come esempio, codifichiamo il primo vettore del nostro dataset di esempio , utilizzando la codifica in ampiezza. Normalizzando il vettore risultante, otteniamo:
e il risultante stato quantistico a 2 qubit sarebbe:
Nell'esempio precedente, il numero di caratteristiche nel vettore non è una potenza di 2. Quando non è una potenza di 2, scegliamo semplicemente un valore per il numero di qubit tale che e aggiungiamo costanti non informative come padding al vettore delle ampiezze (in questo caso, uno zero).
Come nella codifica in base, una volta calcolato lo stato che codificherà il nostro dataset, in Qiskit possiamo usare la funzione initialize per prepararlo:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Un vantaggio della codifica in ampiezza è il requisito di soli qubit per la codifica. Tuttavia, gli algoritmi successivi devono operare sulle ampiezze di uno stato quantistico, e i metodi per preparare e misurare gli stati quantistici tendono a non essere efficienti.
Verifica la tua comprensione
Leggi le domande seguenti, rifletti sulle tue risposte, poi clicca i triangoli per rivelare le soluzioni.
Scrivi lo stato normalizzato per la codifica del seguente vettore (composto da due vettori del nostro dataset di esempio):
utilizzando la codifica in ampiezza.
Risposta:
Per codificare 6 numeri, avremo bisogno di almeno 6 stati disponibili sulle cui ampiezze possiamo codificare. Questo richiederà 3 qubit. Usando un fattore di normalizzazione sconosciuto , possiamo scrivere:
Nota che
Quindi infine,
Per lo stesso vettore di dati scrivi del codice per creare un circuito che carichi queste caratteristiche dei dati usando la codifica in ampiezza.
Risposta:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Potresti dover gestire vettori di dati molto grandi. Considera il vettore
Scrivi del codice per automatizzare la normalizzazione e generare un circuito quantistico per la codifica in ampiezza.
Risposta:
Ci sono molte possibili risposte. Ecco del codice che stampa alcuni passaggi intermedi:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Vedi vantaggi nella codifica in ampiezza rispetto alla codifica in base? Se sì, spiegali.
Risposta:
Potrebbero esserci diverse risposte. Una risposta è che, dato l'ordine fisso degli stati della base, questa codifica in ampiezza preserva l'ordine dei numeri codificati. Spesso verrà anche codificata in modo più denso.
Un vantaggio della codifica in ampiezza è che sono necessari solo qubit per un vettore di dati -dimensionale (a caratteristiche) . Tuttavia, la codifica in ampiezza è generalmente una procedura inefficiente che richiede una preparazione di stato arbitraria, che è esponenziale nel numero di gate CNOT. Detto diversamente, la preparazione dello stato ha una complessità di runtime polinomiale di nel numero di dimensioni, dove , e è il numero di qubit. La codifica in ampiezza "fornisce un risparmio esponenziale in spazio al costo di un aumento esponenziale in tempo"[3]; tuttavia, aumenti del runtime a sono realizzabili in certi casi[4]. Per un'accelerazione quantistica end-to-end, è necessario considerare la complessità del runtime di caricamento dei dati.
Codifica ad angolo
La codifica ad angolo è di interesse in molti modelli QML che utilizzano feature map di Pauli, come le macchine a vettori di supporto quantistiche (QSVM) e i circuiti quantistici variazionali (VQC), tra gli altri. La codifica ad angolo è strettamente correlata alla codifica di fase e alla codifica ad angolo denso, presentate di seguito. Qui useremo "codifica ad angolo" per riferirci a una rotazione in , ovvero una rotazione allontanata dall'asse ottenuta ad esempio con un gate o un gate [1,3]. In realtà, si può codificare i dati in qualsiasi rotazione o combinazione di rotazioni. Ma è comune in letteratura, quindi lo enfatizziamo qui.
Applicata a un singolo qubit, la codifica ad angolo imprime una rotazione attorno all'asse Y proporzionale al valore del dato. Considera la codifica di una singola caratteristica () dal vettore dati di un dataset, :
In alternativa, la codifica ad angolo può essere eseguita usando gate , sebbene lo stato codificato avrebbe una fase relativa complessa rispetto a .
La codifica ad angolo si differenzia dai due metodi precedenti in diversi modi. Nella codifica ad angolo:
- Ogni valore di caratteristica è mappato a un qubit corrispondente, , lasciando i qubit in uno stato prodotto.
- Un valore numerico viene codificato alla volta, anziché un intero insieme di caratteristiche di un punto dati.
- Sono necessari qubit per caratteristiche dei dati, dove . Spesso vale l'uguaglianza. Vedremo come sia possibile nelle prossime sezioni.
- Il circuito risultante ha una profondità costante (in genere la profondità è 1 prima della transpilazione).
Il circuito quantistico a profondità costante lo rende particolarmente adatto all'hardware quantistico attuale. Un'ulteriore caratteristica della codifica dei dati usando (e in particolare, la scelta di usare la codifica ad angolo sull'asse Y) è che crea stati quantistici a valori reali, utili per certe applicazioni. Per la rotazione sull'asse Y, i dati vengono mappati con un gate di rotazione per un angolo reale (Qiskit RYGate). Come per la codifica di fase (vedi sotto), si raccomanda di riscalare i dati in modo che , prevenendo perdita di informazioni e altri effetti indesiderati.
Il seguente codice Qiskit ruota un singolo qubit dallo stato iniziale per codificare un valore dato .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Definiremo una funzione per visualizzare l'azione sul vettore di stato. I dettagli della definizione della funzione non sono importanti, ma la capacità di visualizzare i vettori di stato e le loro variazioni lo è.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Quello era solo un singolo feature di un singolo vettore dati. Quando si codificano caratteristiche negli angoli di rotazione di qubit, ad esempio per il vettore dati lo stato prodotto codificato sarà:
Notiamo che questo è equivalente a
Verifica la tua comprensione
Leggi le domande di seguito, rifletti sulle tue risposte, poi clicca i triangoli per rivelare le soluzioni.
Codifica il vettore dati usando la codifica ad angolo, come descritto sopra.
Risposta:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Usando la codifica ad angolo come descritto sopra, quanti qubit sono necessari per codificare 5 caratteristiche?
Risposta: 5
Codifica di fase
La codifica di fase è molto simile alla codifica ad angolo descritta sopra. L'angolo di fase di un qubit è un angolo reale attorno all'asse a partire dall'asse +. I dati vengono mappati con una rotazione di fase, , dove (vedi Qiskit PhaseGate per maggiori informazioni). Si raccomanda di riscalare i dati in modo che . Questo previene la perdita di informazioni e altri effetti potenzialmente indesiderati[1,2].
Un qubit viene spesso inizializzato nello stato , che è un autostato dell'operatore di rotazione di fase, il che significa che lo stato del qubit deve prima essere ruotato affinché la codifica di fase possa essere implementata. Ha quindi senso inizializzare lo stato con un gate di Hadamard: . La codifica di fase su un singolo qubit significa imprimere una fase relativa proporzionale al valore del dato:
La procedura di codifica di fase mappa ogni valore di caratteristica alla fase di un qubit corrispondente, . Nel complesso, la codifica di fase ha una profondità di circuito pari a 2, incluso il layer di Hadamard, il che la rende uno schema di codifica efficiente. Lo stato multi-qubit codificato in fase ( qubit per caratteristiche) è uno stato prodotto:
Il seguente codice Qiskit prima prepara lo stato iniziale di un singolo qubit ruotandolo con un gate di Hadamard, poi lo ruota di nuovo usando un gate di fase per codificare una caratteristica .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Possiamo visualizzare la rotazione in usando la funzione plot_Nstates che abbiamo definito.
plot_Nstates(states, axis=None, plot_trace_points=True)

Il grafico della sfera di Bloch mostra la rotazione sull'asse Z dove . La freccia verde chiaro mostra lo stato finale.
La codifica di fase è usata in molte feature map quantistiche, in particolare le feature map e , e le feature map di Pauli generali, tra le altre.
Verifica la tua comprensione
Leggi le domande di seguito, rifletti sulle tue risposte, poi clicca i triangoli per rivelare le soluzioni.
Quanti qubit sono necessari per usare la codifica di fase come descritto sopra per memorizzare 8 caratteristiche?
Risposta: 8
Scrivi il codice per caricare il vettore usando la codifica di fase.
Risposta:
Potrebbero esserci molte risposte. Ecco un esempio:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Codifica ad angolo denso
La codifica ad angolo denso (DAE) è una combinazione di codifica ad angolo e codifica di fase. La DAE permette di codificare due valori di caratteristica in un singolo qubit: uno con un angolo di rotazione sull'asse Y, e l'altro con un angolo di rotazione sull'asse : . Codifica due caratteristiche come segue:
Codificare due caratteristiche in un solo qubit comporta una riduzione di nel numero di qubit necessari per la codifica. Estendendo questo a più caratteristiche, il vettore dati può essere codificato come:
La DAE può essere generalizzata a funzioni arbitrarie delle due caratteristiche invece delle funzioni sinusoidali usate qui. Questa viene chiamata codifica generale del qubit[7].
Come esempio di DAE, il codice seguente codifica e visualizza la codifica delle caratteristiche e .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Verifica la tua comprensione
Leggi le domande di seguito, rifletti sulle tue risposte, poi clicca i triangoli per rivelare le soluzioni.
Sulla base della trattazione sopra, quanti qubit sono necessari per codificare 6 caratteristiche usando la codifica densa?
Risposta: 3
Scrivi il codice per caricare il vettore usando la codifica ad angolo denso.
Risposta:
Nota che abbiamo aggiunto un "0" alla fine della lista per evitare il problema di avere un singolo parametro inutilizzato nello schema di codifica.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Codifica con feature map integrate
Codifica in punti arbitrari
L'angle encoding, il phase encoding e il dense encoding preparano stati prodotto con una feature codificata su ogni qubit (o due feature per qubit). Questo li distingue dal basis encoding e dall'amplitude encoding, che fanno uso di stati entangled. Non esiste una corrispondenza 1:1 tra feature del dato e qubit. Nell'amplitude encoding, ad esempio, una feature può corrispondere all'ampiezza dello stato e un'altra all'ampiezza di . In generale, i metodi che codificano in stati prodotto producono circuiti più superficiali e possono memorizzare 1 o 2 feature per qubit. I metodi che usano l'entanglement e associano una feature a uno stato piuttosto che a un qubit portano a circuiti più profondi, e possono mediamente memorizzare più feature per qubit.
La codifica, tuttavia, non deve essere interamente in stati prodotto o interamente in stati entangled come nell'amplitude encoding. Molti schemi di codifica integrati in Qiskit consentono la codifica sia prima che dopo uno strato di entanglement, anziché solo all'inizio. Questo è noto come "data reuploading". Per lavori correlati, si vedano i riferimenti [5] e [6].
In questa sezione utilizzeremo e visualizzeremo alcuni degli schemi di codifica integrati. Tutti i metodi in questa sezione codificano feature come rotazioni su gate parametrizzati su qubit, dove . Si noti che massimizzare il caricamento dei dati per un dato numero di qubit non è l'unica considerazione. In molti casi, la profondità del circuito può essere un fattore ancora più importante del numero di qubit.
Efficient SU2
Un esempio comune e utile di codifica con entanglement è il circuito efficient_su2 di Qiskit. È notevole il fatto che questo circuito possa, ad esempio, codificare 8 feature su soli 2 qubit. Vediamo come funziona e proviamo a capire come sia possibile.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Quando scriviamo il nostro stato, useremo la convenzione di Qiskit secondo cui i qubit meno significativi sono ordinati all'estrema destra, come in o Questi stati possono diventare molto complicati molto rapidamente, e questo raro esempio può aiutare a spiegare perché tali stati vengono raramente scritti esplicitamente.
Il nostro sistema parte dallo stato Fino alla prima barriera (un punto che chiamiamo ), i nostri stati sono:
Questo è semplicemente il dense encoding che abbiamo già visto. Dopo il gate CNOT, alla seconda barriera (), il nostro stato è
Applichiamo ora l'ultimo insieme di rotazioni a singolo qubit e raccogliamo gli stati simili per ottenere:
Probabilmente è troppo complicato da interpretare. Invece, fai un passo indietro e pensa a quanti parametri abbiamo caricato sullo stato: otto. Eppure abbiamo solo quattro stati della base computazionale. A prima vista potrebbe sembrare che abbiamo caricato più parametri di quanti ne abbia senso, poiché lo stato finale può essere scritto come . Si noti, tuttavia, che ciascun fattore è complesso! Scritto così:
Si può vedere che abbiamo effettivamente otto parametri sullo stato su cui codificare le nostre otto feature.
Aumentando il numero di qubit e incrementando il numero di ripetizioni degli strati di entanglement e rotazione, si possono codificare molti più dati. Scrivere esplicitamente le funzioni d'onda diventa rapidamente intrattabile. Possiamo comunque vedere la codifica in azione.
Qui codifichiamo il vettore dati con 12 feature, su un circuito efficient_su2 a 3 qubit, usando ciascuno dei gate parametrizzati per codificare una feature diversa.
In questo vettore dati, le feature sono mostrate in un ordine specifico. Isolatamente, non importa se vengono codificate in questo ordine o nell'ordine inverso. Ciò che è importante è tenerne traccia ed essere coerenti. Si noti nel diagramma del circuito che efficient_su2 assume un certo ordinamento della codifica, riempiendo in particolare il primo strato di gate parametrizzati dal qubit 0 al qubit 2, e poi passando allo strato successivo. Questo non è né coerente né incoerente con la notazione little-endian, poiché qui le feature dei dati non possono essere ordinate per qubit a priori, prima che sia stato specificato un circuito di codifica.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Invece di aumentare il numero di qubit, potresti scegliere di aumentare il numero di ripetizioni degli strati di entanglement e rotazione. Ma ci sono limiti a quante ripetizioni risultano utili. Come già detto, c'è un compromesso: circuiti con più qubit o più ripetizioni degli strati di entanglement e rotazione possono memorizzare più parametri, ma lo fanno a scapito di una maggiore profondità del circuito. Torneremo sulla profondità di alcune feature map integrate più avanti. I prossimi metodi di codifica integrati in Qiskit hanno "feature map" come parte del loro nome. Ripetiamo che codificare dati in un circuito quantistico è una feature mapping, nel senso che porta i dati in un nuovo spazio: lo spazio di Hilbert dei qubit coinvolti. La relazione tra la dimensionalità dello spazio delle feature originale e quella dello spazio di Hilbert dipenderà dal circuito usato per la codifica.
Feature map
La feature map (ZFM) può essere interpretata come un'estensione naturale del phase encoding. La ZFM consiste in strati alternati di gate a singolo qubit: strati di gate di Hadamard e strati di gate di fase. Sia il vettore dati con feature. Il circuito quantistico che esegue la feature mapping è rappresentato come un operatore unitario che agisce sullo stato iniziale:
dove è lo stato fondamentale a qubit. Questa notazione è usata per coerenza con il riferimento [4] di Havlicek et al. Le feature dei dati sono mappate in corrispondenza biunivoca con i qubit corrispondenti. Ad esempio, se hai 8 feature in un vettore dati, utilizzeresti 8 qubit. Il circuito ZFM è composto da ripetizioni di un sottocircuito formato da strati di gate di Hadamard e strati di gate di fase. Uno strato di Hadamard è composto da un gate di Hadamard che agisce su ogni qubit in un registro di qubit, , nella stessa fase dell'algoritmo. Questa descrizione si applica anche a uno strato di gate di fase in cui il qubit -esimo è soggetto all'azione di . Ogni gate ha una feature come argomento, ma lo strato di gate di fase ( è una funzione del vettore dati. L'unitario completo del circuito ZFM con una singola ripetizione è:
Quindi ripetizioni di questo unitario sarebbero
Le feature dei dati, , sono mappate ai gate di fase nello stesso modo in tutte le ripetizioni. Lo stato della feature map ZFM è uno stato prodotto ed è efficiente per la simulazione classica[4].
Per iniziare con un piccolo esempio, un circuito ZFM a due qubit è codificato con Qiskit e disegnato per mostrare la semplice struttura del circuito. Nell'esempio, viene implementata una singola ripetizione, , con il vettore dati . Si noti che questo è scritto nell'ordine standard di un vettore in Python, il che significa che l'elemento -esimo è Siamo liberi di codificare questa feature -esima sul nostro qubit -esimo, o sull'-esimo. Ancora una volta, non può sempre esserci una mappatura 1:1 unica dall'ordine delle feature all'ordine dei qubit, poiché diverse feature map codificano numeri diversi di feature per ogni qubit. Ancora una volta, ciò che è importante è sapere dove viene codificata ciascuna feature. Quando si fornisce una lista di parametri alla feature map , questa codificherà la feature 0 della lista sul qubit meno significativo con un gate parametrizzato, come nel qubit 0. Seguiremo quindi questa convenzione quando eseguiamo l'operazione a mano. Codificheremo sul qubit -esimo, e sul qubit -esimo.
L'operatore unitario del circuito ZFM agisce sullo stato iniziale nel seguente modo:
La formula è stata riorganizzata attorno al prodotto tensore per enfatizzare le operazioni su ciascun qubit. Il seguente codice Qiskit usa esplicitamente i gate di Hadamard e di fase per mostrare la struttura della ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Ora codifichiamo lo stesso vettore dati in un circuito ZFM con tre ripetizioni, , usando la classe z_feature_map di Qiskit, che nel complesso ci fornisce la feature map quantistica . Per impostazione predefinita nella classe z_feature_map, i parametri vengono moltiplicati per 2 prima di essere mappati al gate di fase . Per riprodurre le stesse codifiche di cui sopra, dividiamo per 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Chiaramente questa è una mappatura diversa da quella eseguita a mano sopra, ma si noti la coerenza nell'ordinamento dei parametri: è stato nuovamente codificato sul qubit -esimo.
Puoi usare la ZFM tramite la classe ZFM di Qiskit; puoi anche usare questa struttura come ispirazione per costruire la tua feature mapping personalizzata.
Feature map
La feature map (ZZFM) estende la ZFM con l'inclusione di gate entangling a due qubit, in particolare il gate di rotazione , . Si congettura che la ZZFM sia generalmente costosa da calcolare su un computer classico, a differenza della ZFM.
implementa un'interazione ed è massimamente entangling per . può essere decomposto in una serie di gate su due qubit, come mostrato nel seguente codice Qiskit che usa il gate RZZ e il metodo decompose della classe QuantumCircuit. Codifichiamo una singola feature del vettore dati :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Come spesso accade, lo vediamo rappresentato come un'unica unità simile a un gate, finché non usiamo .decompose() per vedere tutti i gate costituenti.
qc.decompose().draw("mpl", scale=1)

I dati sono mappati con una rotazione di fase sul secondo qubit. Il gate entangla i due qubit su cui opera con un grado di entanglement determinato dal valore della feature codificata.
Il circuito ZZFM completo consiste in un gate di Hadamard e un gate di fase, come nella ZFM, seguiti dall'entanglement descritto sopra. Una singola ripetizione del circuito ZZFM è:
dove contiene uno strato di gate ZZ strutturato secondo uno schema di entanglement. Diversi schemi di entanglement sono mostrati nei blocchi di codice seguenti. La struttura di include anche una funzione che combina le feature dei dati dei qubit che vengono entanglati nel modo seguente. Supponiamo che il gate debba essere applicato ai qubit e . Nello strato di fase, questi qubit hanno gate di fase che codificano rispettivamente e su di essi. L'argomento di non sarà semplicemente una di queste feature o l'altra, ma una funzione spesso denotata con (da non confondere con l'angolo azimutale):
Lo vedremo in diversi esempi qui di seguito. L'estensione a ripetizioni multiple è la stessa del caso z_feature_map:
Poiché gli operatori sono diventati più complessi, iniziamo codificando un vettore dati con una ZZFM a due qubit e una ripetizione usando il seguente codice:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Per impostazione predefinita in Qiskit, le feature vengono mappate insieme a tramite questa funzione di mappatura . Qiskit consente all'utente di personalizzare la funzione (o dove è l'insieme delle coppie di qubit accoppiati tramite gate ) come passo di pre-elaborazione.
Passando a un vettore dati quadridimensionale e mappandolo su una ZZFM a quattro qubit con una ripetizione, possiamo iniziare a vedere la mappatura per varie coppie di qubit. Possiamo anche vedere il significato di entanglement "lineare":
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Nello schema di entanglement lineare, le coppie di qubit vicini (numerati) in questo circuito vengono entanglate. In Qiskit sono presenti altri schemi di entanglement integrati, tra cui circular e full.
Feature map di Pauli
La feature map di Pauli (PFM) è la generalizzazione della ZFM e della ZZFM all'uso di gate di Pauli arbitrari. La feature map di Pauli assume una forma molto simile alle due feature map precedenti. Per ripetizioni della codifica delle feature del vettore
Per la PFM, è generalizzato a un operatore unitario di espansione di Pauli. Qui presentiamo una forma più generalizzata delle feature map considerate finora:
dove è un operatore di Pauli, . Qui è l'insieme di tutte le connettività tra qubit determinate dalla feature map, incluso l'insieme dei qubit su cui agiscono i gate a singolo qubit. Vale a dire, per una feature map in cui il qubit 0 fosse soggetto a un gate di fase, e i qubit 2 e 3 fossero soggetti a un gate , l'insieme includerebbe . scorre attraverso tutti gli elementi di quell'insieme. Nelle feature map precedenti, la funzione riguardava esclusivamente i gate a singolo qubit o esclusivamente quelli a due qubit. Qui la definiamo in generale:
Per la documentazione, consulta la documentazione della classe Pauli feature map di Qiskit). Nella ZZFM, l'operatore è limitato a .
Un modo per comprendere l'unitario di cui sopra è attraverso l'analogia con il propagatore in un sistema fisico. L'unitario sopra è un operatore di evoluzione unitaria, , per un'Hamiltoniana, , simile al modello di Ising, dove il parametro temporale, , è sostituito da valori dei dati per guidare l'evoluzione. L'espansione di questo operatore unitario fornisce il circuito PFM. Le connettività entangling in possono essere interpretate come accoppiamenti di Ising in un reticolo di spin.
Consideriamo un esempio di operatori di Pauli e che rappresentano quelle interazioni di tipo Ising. Qiskit fornisce una classe pauli_feature_map per istanziare una PFM con una scelta di gate a singolo qubit e a qubit, che in questo esempio verranno passati come stringhe di Pauli 'Y' e 'XX'. Tipicamente, è 1 o 2 per interazioni a singolo qubit e a due qubit rispettivamente. Lo schema di entanglement è "lineare", il che significa che solo i qubit vicini nel circuito quantistico sono accoppiati. Si noti che questo non corrisponde ai qubit vicini sul computer quantistico fisico, poiché questo circuito quantistico è uno strato di astrazione.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit fornisce un parametro, , nelle feature map di Pauli per controllare il ridimensionamento delle rotazioni di Pauli.
Il valore predefinito di è . Ottimizzando il suo valore nell'intervallo, ad esempio, è possibile allineare meglio un kernel quantistico ai dati.
Galleria di feature map di Pauli
Qui visualizziamo varie feature map di Pauli per circuiti a due qubit per avere un quadro migliore della gamma di possibilità.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Quanto sopra può naturalmente essere esteso per includere altre permutazioni e ripetizioni delle matrici di Pauli. I lettori sono incoraggiati a sperimentare con tali opzioni.
Revisione delle feature map integrate
Hai visto diversi schemi per codificare dati in un circuito quantistico:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
Hai visto come costruire le proprie feature map usando questi schemi di codifica, e hai visto quattro feature map integrate che sfruttano l'angle encoding e il phase encoding:
- Efficient SU2
- Feature map Z
- Feature map ZZ
- Feature map di Pauli
Queste feature map integrate differivano tra loro in diversi modi:
- La profondità per un dato numero di feature codificate
- Il numero di qubit richiesti per un dato numero di feature
- Il grado di entanglement (ovviamente correlato alle altre differenze)
Il codice seguente applica queste quattro feature map integrate alla codifica di un insieme di feature, e traccia la profondità a due qubit del circuito risultante. Poiché i tassi di errore a due qubit sono molto più elevati rispetto ai tassi di errore dei gate a singolo qubit, si potrebbe essere principalmente interessati alla profondità dei gate a due qubit. Nel codice seguente, otteniamo i conteggi di tutti i gate in un circuito decomponendo prima il circuito e poi usando count_ops(), come mostrato di seguito. Qui i gate a due qubit che ci interessano sono i gate 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
In generale, le feature map Pauli e ZZ risulteranno in una maggiore profondità del circuito e in un numero più elevato di gate a 2 qubit rispetto a efficient_su2 e alle feature map Z.
Poiché le feature map integrate in Qiskit sono ampiamente applicabili, spesso non avremo bisogno di progettarne di nostre, specialmente nella fase di apprendimento. Tuttavia, gli esperti di quantum machine learning probabilmente torneranno sull'argomento della progettazione delle proprie feature mapping, affrontando due sfide complesse:
-
Hardware moderno: la presenza di rumore e l'elevato overhead del codice di correzione degli errori significano che le applicazioni attuali dovranno considerare aspetti come l'efficienza hardware e la minimizzazione della profondità dei gate a due qubit.
-
Mappature adatte al problema in questione: una cosa è dire che la
zz_feature_map, ad esempio, è difficile da simulare classicamente, e quindi interessante. È tutta un'altra cosa che lazz_feature_mapsia idealmente adatta al tuo task di machine learning o insieme di dati. Le prestazioni di diversi circuiti quantistici parametrizzati su diversi tipi di dati sono un'area di ricerca attiva.
Concludiamo con una nota sull'efficienza hardware.
Feature mapping hardware-efficient
Una feature mapping hardware-efficient è quella che tiene conto dei vincoli dei computer quantistici reali, nell'interesse di ridurre il rumore e gli errori nel calcolo. Quando si eseguono circuiti quantistici su computer quantistici near-term, ci sono molte strategie per mitigare il rumore intrinseco all'hardware. Una strategia principale per l'efficienza hardware è la minimizzazione della profondità del circuito quantistico, in modo che il rumore e la decoerenza abbiano meno tempo per corrompere il calcolo. La profondità di un circuito quantistico è il numero di passi gate allineati temporalmente necessari per completare l'intero calcolo (dopo l'ottimizzazione del circuito)[5]. Si ricordi che la profondità del circuito logico astratto può essere molto inferiore alla profondità dopo che il circuito è stato transpilato per un computer quantistico reale.
La transpilazione è il processo di conversione del circuito quantistico da un'astrazione di alto livello a uno pronto per essere eseguito su un computer quantistico reale, tenendo conto dei vincoli dell'hardware. Un computer quantistico ha un insieme nativo di gate a singolo qubit e a due qubit. Ciò significa che tutti i gate nel codice Qiskit devono essere transpilati nell'insieme dei gate hardware nativi. Ad esempio, in ibm_torino, un QPU dotato di un processore Heron r1 e completato nel 2023, i gate nativi o di base sono {CZ, ID, RZ, SX, X}. Questi sono rispettivamente il gate controlled-Z a due qubit e i gate a singolo qubit chiamati identità, rotazione-, radice quadrata di NOT e NOT, che forniscono un insieme universale. Quando si implementano gate multi-qubit come sottocircuito equivalente, sono necessari gate fisici a due qubit, insieme ad altri gate a singolo qubit disponibili nell'hardware. Inoltre, per eseguire un gate a due qubit su una coppia di qubit che non sono fisicamente accoppiati, vengono aggiunti gate SWAP per spostare gli stati dei qubit tra qubit che consentono l'accoppiamento, il che porta a un'inevitabile estensione del circuito. Utilizzando l'argomento optimization che può essere impostato da 0 fino a un livello massimo di 3. Per un maggiore controllo e personalizzazione, la pipeline del transpiler può essere gestita con il Qiskit Pass Manager. Consulta la documentazione del Transpiler di Qiskit per ulteriori informazioni sulla transpilazione.
In Havlicek et al. 2019 [2], uno dei modi in cui gli autori raggiungono l'efficienza hardware è usando la feature map perché è un'espansione del secondo ordine (vedi la sezione "Feature map " sopra). Un'espansione di ordine ha gate a qubit. I computer quantistici IBM® non hanno gate nativi a qubit, dove , quindi implementarli richiederebbe la decomposizione in gate CNOT a due qubit disponibili nell'hardware. Un secondo modo in cui gli autori minimizzano la profondità è scegliendo una topologia di accoppiamento che si mappa direttamente agli accoppiamenti dell'architettura. Un'ulteriore ottimizzazione che intraprendono è il targeting di un sottocircuito hardware connesso in modo adeguato e con prestazioni migliori. Ulteriori aspetti da considerare sono la minimizzazione del numero di ripetizioni della feature map e la scelta di uno schema di entanglement personalizzato a bassa profondità o "lineare" invece dello schema "completo" che entangla tutti i qubit.

Il grafico sopra mostra una rete di nodi e archi che rappresentano rispettivamente qubit fisici e accoppiamenti hardware. La mappa di accoppiamento e le prestazioni di ibm_torino sono mostrate con tutti i possibili gate di accoppiamento CZ a due qubit. I qubit sono codificati a colori su una scala basata sul tempo di rilassamento T1 in microsecondi (μs), dove tempi T1 più lunghi sono migliori e sono in una tonalità più chiara. Gli archi di accoppiamento sono codificati a colori dall'errore CZ, dove le tonalità più scure sono migliori. Le informazioni sulle specifiche hardware sono accessibili nello schema di configurazione del backend hardware IBMQBackend.configuration().
Riferimenti
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()